Global Digital Elevation Models and Accessing Model Error Propagation and Uncertainty
An Analysis of Mount Kilimanjaro, Tanzania
During labs 3 and 4, we conducted an hydology analysis in SAGA Version 6.2. We derived a variety of terrain products from a model built in SAGA, and then further accessed the sources of error by comparing several different sources of elevation data.
Gathering Elevation Data
I used both ASTER data from the US and Japan Science Teams, and SRTM data from NASA in this analysis. Using the Earth Data Search website, I downloaded the Aster Global Digital Elevation Model V003, NASA Shuttle Radar Topography Mission Global 1 arc second V003, and the associated number v003 file for NASA SRTM. Using Mount Kilimanjaro, Tanzania as the study region, I downloaded tiles S0E037 and S04E037. Then, for the SRTM data we have to convert the numbr data into usable grids using a python script developed by Professor Holler. Now the data is ready to view and analyze in SAGA by using Import Raster.
Download the Data:
NASA/METI/AIST/Japan Spacesystems, and U.S./Japan ASTER Science Team. ASTER Global Digital Elevation Model V003. 2019, distributed by NASA EODIS Land Processes DAAC, https://doi.org/10.5067/ASTER/ASTGTM.003
NASA JPL. NASA Shuttle Radar Topography Mission Global 1 arc second. 2013, distributed by NASA EOSDIS Land Processes DAAC. , https://doi.org/10.5067/MEaSUREs/SRTM/SRTMGL1.003, and it’s number grids: https://lpdaac.usgs.gov/products/srtmgl1nv003/
Get the Software:
- SAGA Project website: http://www.saga-gis.org
- SAGA Open source code & download: https://sourceforge.net/projects/saga-gis/
- SAGA Tool Reference: http://www.saga-gis.org/saga_tool_doc/6.2.0/index.html
Making a Global DEM Model
Using the ASTER data acquired above, I conducted a basic terrain analysis around Mount Kilimanjaro, Tanzania. This analysis was conducted on SAGA open source GIS. Below are the steps of analysis: creating an analytical hillshade visualization, detecting sinks and determining flow through them, removing sinks from the DEM by filling them, calculating flow accumulation, and mapping a channel network to show where streams are.
After projecting the grid into the correct UTM zone (zone 37), rather than using a WGS projection, I created a hillshade visualization. I used an azimuth of 315 and a height of 45, which is standard to show the sun coming from the top left corner.

I then ran a sink drainage route tool to determine sinks and where hydrological features might run through them. The blue shows no sinks, and the colored dots show different values of sinks.

Then I filled the sinks to create another DEM with the sinks filled in. This looks similar to the original data input but will have all holes due to real topographical changes or data errors removed.
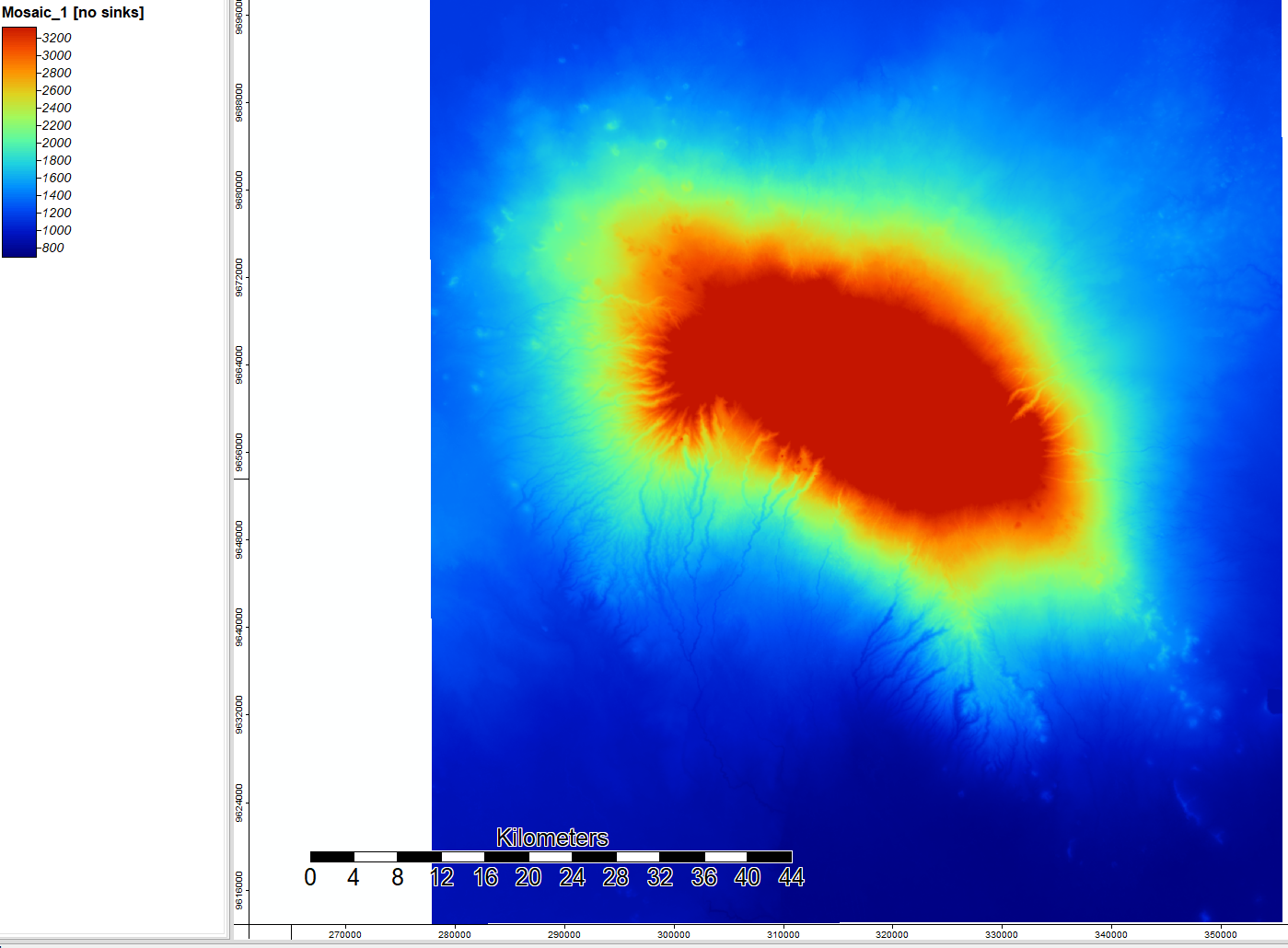
Now we can use a flow accumulation tool to calculate where the water will go. Each value shows accumulation of water in each cell, with darker values showing more accumulation.

Finally, I ran a channel network to determine where the streams in this landscape are. Once enough water accumulates in each cell from the flow accumulation (as the value increases), then the model assumes that a stream has formed. I overlayed this map onto the hillshade visualization to better see and understand the landscape terrain.

Batch Processing and Error Propagation
For this lab, we looked more closely at the different data sources SRTM and ASTER data pull from. For each pixel, many different scenes are processed from different sources, and sometimes pixels with missing data are filled in from other sources or interpolated from surrounding cells. Digging into the source of data and error can help us understand how error can propagate through models and how to better control for it.
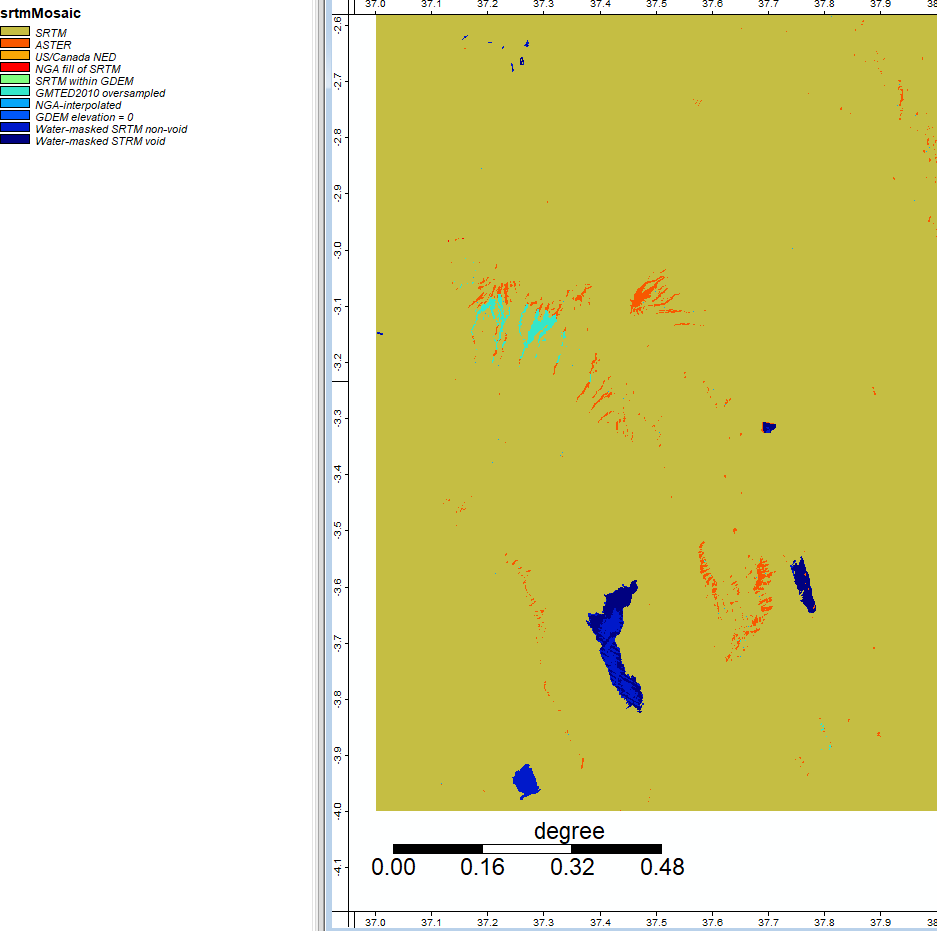
We started by writing and running batch scripts to automate much of the hydological analysis process. Using batch scripts make it much easier to change the inputs to different steps and compare the outcome, and also allow the user to quickly run a hydrological analysis on their own region with both ASTER use the model and SRTM use the model data. In order to automate the tools, I used the same process described above, but used the specific library and tool number under the properties of each tool in SAGA. From there, I used different options for each tool in command prompts to automate an analysis. We brought in the NUM files for both ASTER use the model and SRTM use the model and mosaicked them together with the correct UTM projection to visualize the sources of data for each, and then trace back error to different sources of data.
This image shows the project of a mosaicked and projected NUM file for SRTM, where the majority of the image is data from SRTM (mustard color), but certain areas - particularly steep mountain regions and water bodies - stand out as data from different sources.
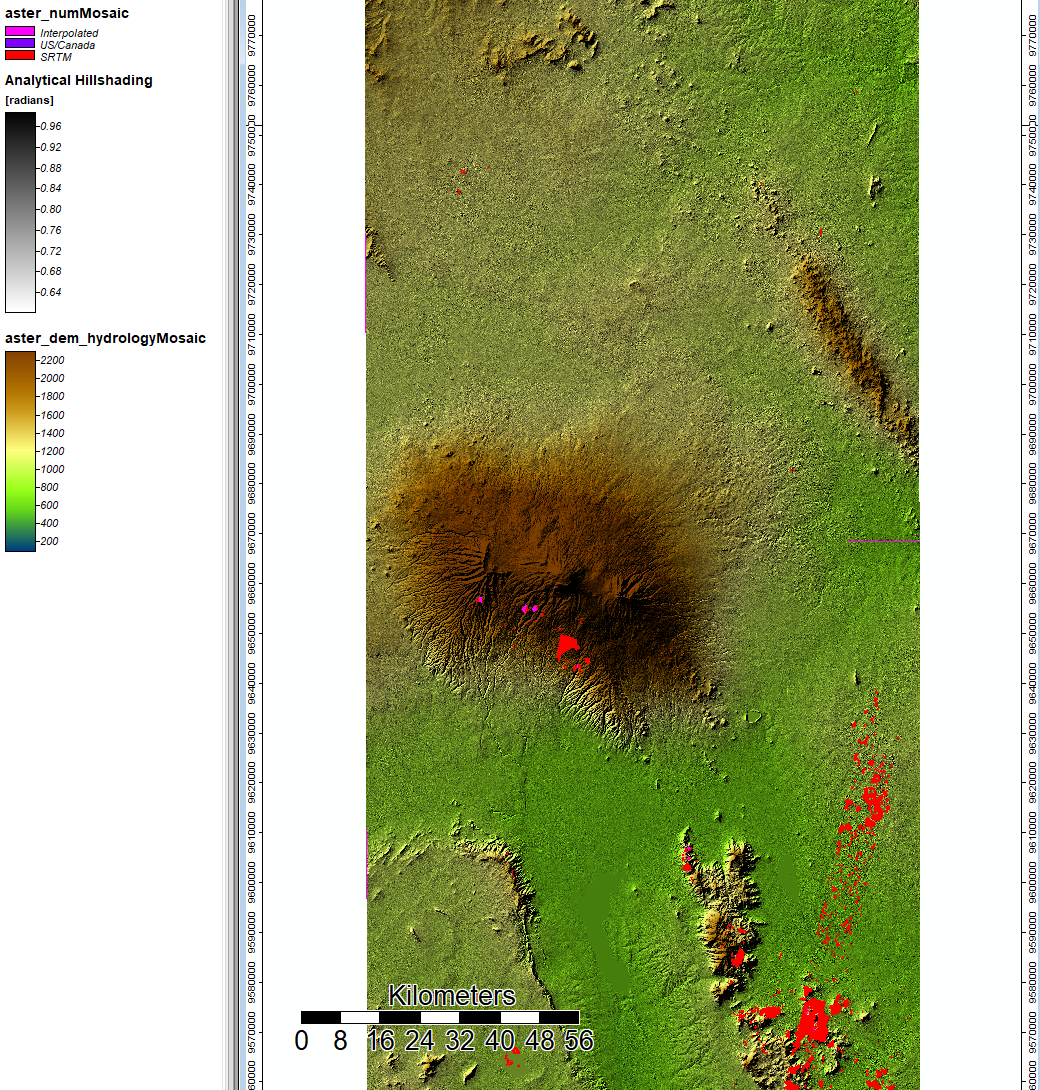
This image shows the ASTER DEM and hillshade visualizations with sources of data not from ASTER. Primarily, the other data sources for these areas are from SRTM or interpolated from neighboring data.
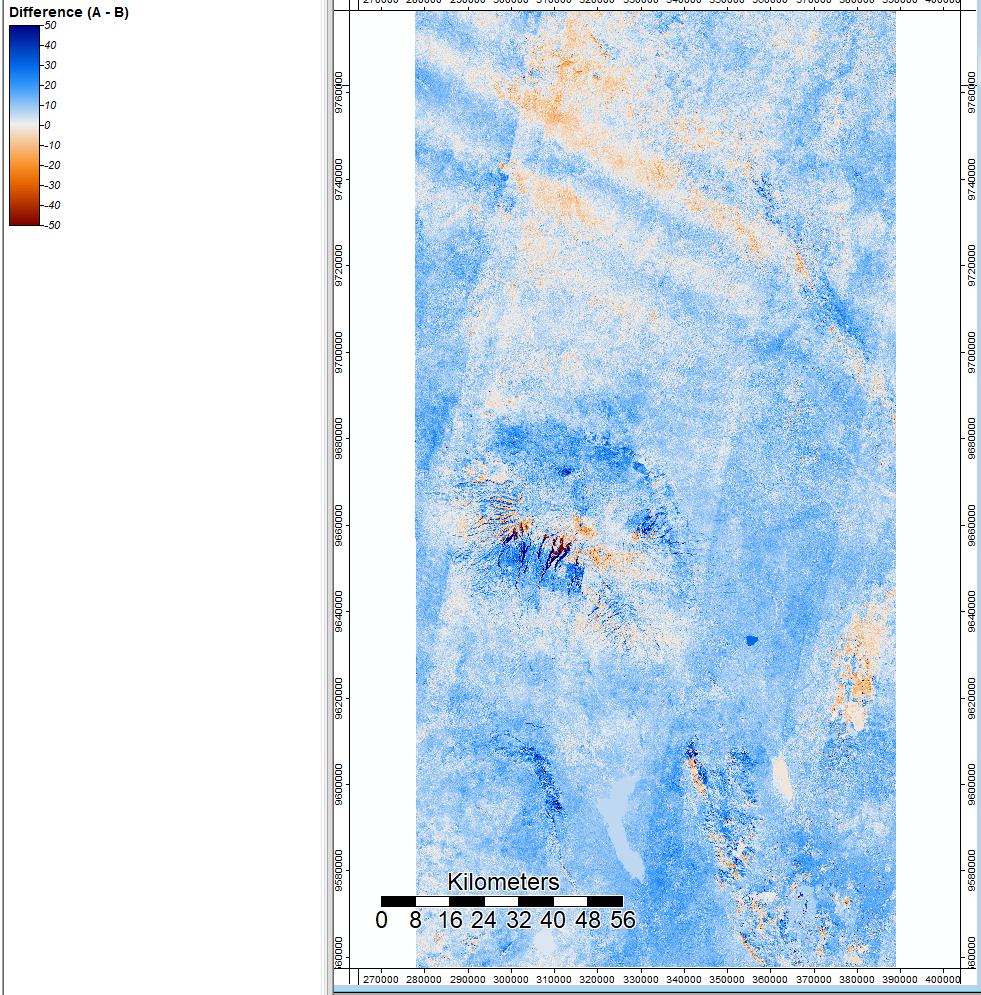
After running both ASTER and SRTM models of the Mt. Kilimanjaro region, I took the difference between the two elevation models to visualize the places of variation and potential error. This image shows SRTM-ASTER using the grid difference tool in SAGA, and you can see that the redder and bluer spots have larger variation between the two layers, and whiter colors are more consistent across both data sources.
I ran this same tool to look at the difference in flow accumulation between SRTM and ASTER. Though there are more red and blue points across the image, three main spots jump out as containing large differences, and several places contain more white which shows more consistency across the flow accumulation for SRTM and ASTER.
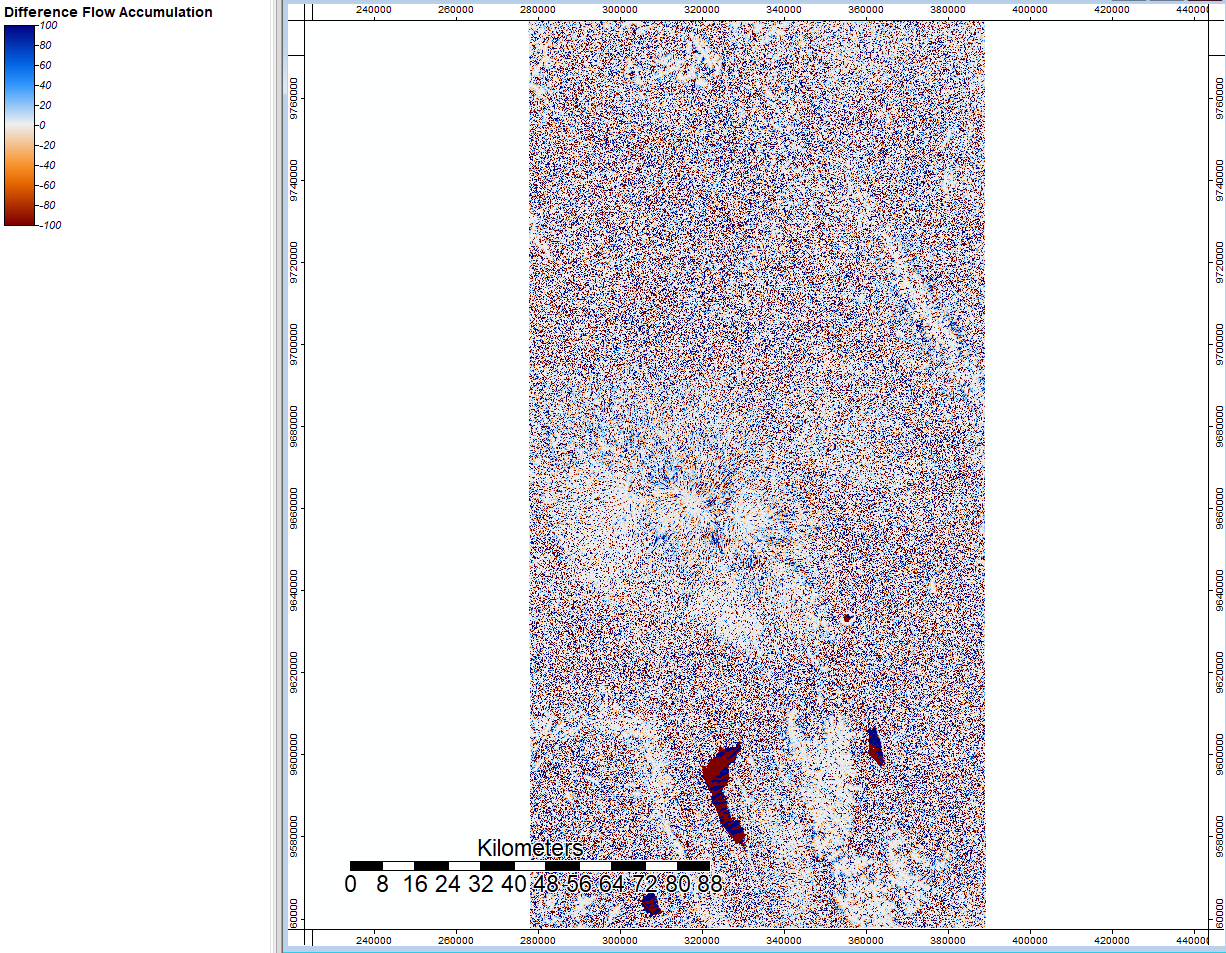
With all of this information, we can see that steep mountainous slopes and areas with large bodies of water (e.g. lake, canal) can generate error in our analysis and produce different results. The flow accumulation and channel network analysis have larger variation about the water bodies because it is a flat surface; it cannot accuracte tell movement of water with no elevation and cannot accurately determine shorelines. These three areas are three large lakes, as you can tell from background terrain imagery.
Based on this analysis, I would say that ASTER data is preferable because it has more accurate sources of data in the very steep slope regions - where error tends to exist the most. For the SRTM data, the sections of very steep slope (shown in bright blue in the visualization of NUM data sources) are taken from ASTER data, as ASTER has more precise measurements for the steep terrain. This is my largest concern for sources of error that could impact the outcomes of an analysis: because water flows off the mountainous regions of high elevation, having accurate data in these regions is important for the outcome of the results. Data that is interpolated from surrounding pixels in mountainous regions is not likely to be accurate because of the large disparity of elevation changes. This is a larger concern for the result of the analysis than the error over water bodies, which can more easily be accounted for. For either ASTER or SRTM, it would help reduce the error by masking out the large bodies of water so they are not factored into the analysis. Additionally, because water collects in the spots, they are at the end of the flows and channels so would not affect the greater analysis.